How disciplined engineering helps Solve Education! turn learning into livelihood at scale
It’s the first day of a new campaign. Within the same hour, a whole wave of learners opens edbot.ai for the first time. A few days later, the next rollout begins in another country, then another. At quieter hours, the load drops. Fewer learners are online, and the system should cost us a fraction of what it does at peak.
From the learner’s perspective, this should be invisible. The app loads, the lesson starts, and Coach Ed responds. From an engineering standpoint, a lot has to go right for that to happen consistently across multiple countries every day.
For us at Solve Education!, this is not only a technical concern. Our model is built on persistence — helping young people stay engaged with learning long enough to build real, income-relevant skills, and eventually move into a livelihood. Persistence is the engine of the entire model. Every time the platform breaks, slows, or feels unreliable, learners lose momentum. And momentum, once lost, is expensive to rebuild.
That’s why engineering reliability sits at the heart of how we deliver the mission. It is not separate from the work. It is what makes the work possible at scale.
At the same time, the pressure to ship faster is everywhere right now. AI agents write code, suggest architecture, and automate workflows. But faster development without the right foundations just means problems compound faster. Here’s how we hold the balance, and why it matters beyond the engineering team.
What scalable actually means
Scalable doesn’t mean a powerful server. It means the system grows and shrinks with demand, on its own. When a new partner launches a campaign and thousands of learners come online together, the platform expands to meet them. When traffic eases, it contracts. For Solve Education!, this matters in two ways. First, it protects the learner’s experience: nobody waits for a slow app or hits an error at the moment they decide to log in and learn. Second, it protects the resources we’ve been entrusted with: we don’t pay for capacity we aren’t using, which means more of every dollar from funders and partners stays available for the mission.

Three components make this work:
- Load balancer. Every request to the platform passes through here first. It distributes traffic evenly and routes around any unresponsive server. From the learner’s side, this means the app stays available even when something behind the scenes is failing.
- Auto-scaling app servers. We run on AWS ECS Fargate, which lets the platform automatically add capacity when demand rises and remove it when demand falls. For learners, this means a campaign rollout doesn’t slow down just because everyone arrived at once. For the organisation, it means we are not paying for idle capacity overnight.
- Scalable database. The data layer scales with the rest of the system. This avoids a common trap where the application can handle the load but the database can’t, which would create the same broken experience for the learner as if the database didn’t scale at all.
The result is consistency. A learner in Indonesia and a learner in Malaysia get the same experience whether they’re the tenth or the ten-thousandth person on the platform that day. Consistency is what lets a learner trust that when they show up, the platform shows up too.
Why scaling broken code breaks learner trust faster
Reliable infrastructure only matters if the code running on it is reliable too. Half the work of keeping the platform stable is the code we ship into it.
This matters more now that AI tools are part of how development works. AI generates code quickly. It can also reproduce insecure code and produce things that look correct but break under load. Whether code comes from a human, an AI assistant, or a mix of both, it goes through the same checks before it reaches learners.
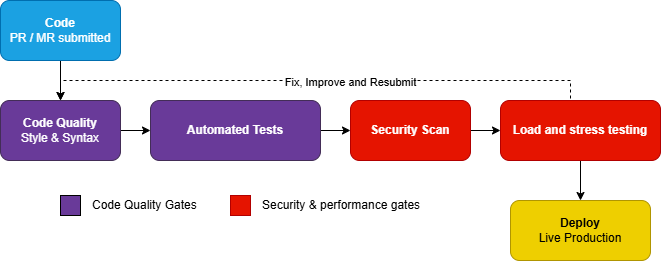
Our pipeline runs automatically on every code change. If any step fails, nothing ships. There are four gates, each protecting a different part of the learner experience:
- Code quality checks. Catches inconsistencies and small mistakes early. The benefit for learners is indirect but real: a clean codebase is easier for the team to maintain, which means we spend less time fixing avoidable problems and more time building features that help learners stay engaged.
- Automated tests. Verify that new changes don’t break existing behaviour. When a learner opens a lesson, finishes an exercise, or earns a milestone, hundreds of small interactions happen behind the scenes. Tests make sure that adding something new doesn’t quietly break something that was already working, which would silently erode the learner’s experience.
- Security scanning. Checks every change for known vulnerability patterns: exposed credentials, insecure dependencies, common attack vectors. The cost of skipping this is asymmetric. Most changes are fine, but the one that introduces a vulnerability can compromise learner data or platform integrity. For a non-profit serving young people in vulnerable contexts, that trust, once broken, is very hard to rebuild.
- Load and stress testing. Simulates peak traffic before a release goes live, so we know how the system behaves under pressure. We want to discover where the system might break in a controlled environment, not during a learner’s lesson.
What changes when AI is involved
There is a lot of vague talk about “AI in engineering.” Here is what it actually means for us.
When the team uses AI to speed up development, the engineering role shifts. Less time writing routine code, more time on the questions that actually move the product forward: understanding what learners are struggling with, what’s working, and what isn’t.
The way those questions get answered matters. Our engineers are expected to drive product decisions through small, observable experiments. Releasing a feature to a subset of learners, watching how they actually behave, and deciding whether to scale it, iterate on it, or shut it down. That experimentation discipline is how the product stays focused on what genuinely helps learners persist, build skills, and move toward livelihood, rather than accumulating features that don’t earn their place.
The pipeline we run is what makes this faster pace safe. Without it, more experimentation would mean more risk. With it, we can move quickly on what helps learners and still hold the line on quality, security, and reliability.
A few things we’ve learned

The platform we run today exists because we built it deliberately. Each piece was put in place because the alternative had a real cost: slow incident response, inconsistent quality, or a system too fragile to extend without breaking learner trust.
Three things have stuck with us from building this.
First, understanding why a system is built the way it is matters more than knowing how it works. When we add new services or roll out new capabilities, the groundwork has to support them. That’s only possible if you know what each layer is for and what each layer is protecting.
Second, discipline is easier to sustain when it’s built into the process rather than left to individuals. The pipeline enforces the standards. The infrastructure scales itself. That consistency is what lets a small team deliver reliably across countries and partner contexts.
Third, engineering choices are stewardship choices. When the platform scales down at quieter hours, that’s not just good architecture; it’s resources that stay available for the mission. Every choice we make about how the system runs is also a choice about how we use the trust funders and partners’ place in us.
All of this comes back to the same point. Every learner who opens edbot.ai and gets the lesson they came for is one more day of momentum, one more piece of the persistence that the entire learning-to-livelihood model depends on. The platform staying up is what gives that model a chance to work.